Slimme monitoring van machines op basis van ruwe datasets

Slimme monitoring van machines op basis van ruwe datasets
Machinemonitoring is de combinatie van hardware- en softwaretools waarmee we de ruwe informatie die vanuit de machine beschikbaar is, kunnen evalueren. Door machinemonitoring krijgen eindgebruikers een beter inzicht in de betrouwbaarheid en uptime van hun industriële machines en kan applicatiekennis vastgelegd worden. Met deze kennis kunnen we vervolgens de systemen/processen verbeteren omdat ze inzichten levert in de redenen waarom deze systemen/processen zouden kunnen falen.
Hoe werkt machinemonitoring?
Historisch gezien waren industriële machines helemaal niet verbonden met de cloud. Bijgevolg kon alleen de lokale machinecontroller (via edge-apparatuur) de meetwaarden van de sensoren van de machine uitlezen en gebruiken. Op basis hiervan werden vervolgens verschillende algoritmen op deze controllers uitgevoerd. Dit bleek in de praktijk echter zeer moeilijk te zijn wegens een moeilijke toegang tot de gegevens, wat resulteerde in beperkte mogelijkheden tot analyse en verdere verbetering van deze algoritmen.
In de voorbije jaren hebben het Internet of Things (IoT) en de verdere ontwikkeling van edge computing echter geleid tot:
- Meer connectiviteit van machine naar cloud; en
- Meer rekenkracht op de machine zelf{Qiu2020}.
Nu steeds meer machines en controllers met de cloud verbonden zijn{Rüßmann2015}, is er een enorme hoeveelheid gegevens beschikbaar. Bijvoorbeeld in een grote productielijn, waar veel gegevens worden gegenereerd vanuit een machinepark dat onder vergelijkbare omstandigheden werkt. Hierdoor is het nu wel mogelijk om bestaande statusmonitoring- (CM > Condition Monitoring) en/of anomaliedetectie- (AD) algoritmen te analyseren en hieruit kennis te vergaren. Deze algoritmen verwerken de gegevens lokaal en uploaden ze naar de cloud. Hier worden ze opgeslagen en beoordeeld, hetzij op basis van de domeinkennis van de gebruiker, hetzij met behulp van machine learning- of soortgelijke technieken. Toch zijn deze verzamelde gegevens vaak onbruikbaar, wegens té uitvoerig of overbodig en genereren ze dus geen echte inzichten.
Continue of periodieke monitoring?
Er zijn in principe twee veelgebruikte monitoringsystemen:
- Een systeem dat periodiek alle karakteristieken naar een online database stuurt;
- Een systeem dat continu alle karakteristieken naar een online database stuurt.
Beide opties hebben echter nadelen:
- Het periodiek verzenden van gegevens kan resulteren in een dataset die geen correct overgangsgedrag vertoont en die kritische informatie mist om het systeem correct te analyseren, zoals potentiële defecten die alleen zichtbaar zijn in hoogfrequente ruwe gegevenssignalen.
- Het continu versturen van gegevens leidt niet alleen tot hoge kosten voor gegevensoverdracht en cloudopslag, maar wordt vaak ook beperkt door de bandbreedtecapaciteit van uw internetverbinding.
Dezelfde logica geldt wanneer hoogfrequente ruwe gegevens met waardevolle machine-informatie periodiek of continu naar de cloud worden gestuurd. Het is een complex verhaal omdat systeemfabrikanten voorzichtig zijn met cloudverbindingen en de hiermee gepaard gaande veiligheidsrisico's.
Flanders Make softwarekader
Voor de slimme monitoring van machines ontwikkelde Flanders Make een softwarekader met een hybride aanpak. Enerzijds verzenden we hoogfrequente ruwe data, anderzijds beperken we de redundantie van de verzonden gegevens zoveel mogelijk, zodat een volledige, maar compacte en waardevolle dataset beschikbaar is in de cloud. We gebruiken dit kader voor het (fijn) afstemmen of updaten van CM- en AD-parameters, terwijl de transmissie- en opslagvereisten haalbaar blijven. Met ons softwarekader willen we de volgende doelstellingen bereiken:
- Compacte maar representatieve datasets die voldoende gedetailleerd zijn voor verdere analyse;
- Debugging van de bestaande toepassingslogica;
- Monitoring en opleiding van modellen.
Het door ons ontwikkelde kader is zeer modulair en gemakkelijk configureerbaar, zodat de specifiek beoogde dataset kan worden aangepast aan de verworven kennis. Dergelijke minimale datasets zullen de cloudopslag- en transmissiekosten, die vaak de grootste kostenpost vormen, kunnen verminderen en zo de bestaande beperkingen kunnen opheffen.
Het kader is gebaseerd op lokale apparaten (aangeduid als "edge-apparaten") die – via de data-interface – grote hoeveelheden gegevens verzamelen (productiegegevens, systeemidentificatiegegevens...), vervolgens gebruiken we deze data voor controle en/of systeemoptimalisering. ‘Edge intelligence’ zorgt ervoor dat alleen interessante gegevens naar de cloud worden gestuurd. Er kunnen meerdere edge-apparaten zijn (het aantal van deze apparaten is niet vooraf bepaald of vastgesteld), maar er is slechts één cloud.
Hieronder vindt u een stroomdiagram van de algemene architectuur:

De edge-apparatuur heeft de volgende belangrijke functies:
- Gegevensontvanger: de edge-apparatuur verwerkt verschillende soorten gegevensstromen (continue gegevensstroom, op gebeurtenissen gebaseerde gegevens, salvo’s van snel overgedragen gegevens, metagegevens)
- Gegevensomzetter: de edge-apparatuur zet deze gegevens om in een gemeenschappelijk gegevensformaat dat voor de volgende gegevensstroom (een "snapshot” genoemd) gebruikt kan worden
- Functiecalculator: biedt algemene "functieberekeningen" voor gebruik door de intelligente trigger
- Edge-opslag: opslag van lokale informatie die de machine al kent om redundante gegevens te vermijden
- Intelligente trigger: een aanpasbaar kader waarmee regels kunnen worden vastgesteld over wanneer welke gegevens moeten worden verzonden
- Gegevenszender: zorgt ervoor dat de gegevens vanuit de edge-apparatuur naar de cloud worden verzonden
De cloud heeft de volgende functies:
- Cloudopslag: Acceptatie van de door de edge-apparatuur verzonden gegevens en opslag in zijn database(s) (DB). Deze gegevens bevatten zowel snapshotgegevens (Snapshot-DB, met ruwe gegevensmetingen en -functies) als verwerkte gegevens die worden gebruikt als input voor de intelligente triggerberekeningen door edge-apparaten (zoals een database met bezochte werkpunten – werkpunt-DB).
Andere functies die in de cloud worden ondersteund:
- Gegevensanalyse om de "intelligente trigger" in de edge-apparaten te verbeteren. Dit vereist communicatie vanuit de cloud naar de edge-apparaten om de lokale triggeringactiviteiten en de functie voor toegang tot de gegevens voor analyse bij te werken.
- Rekenkracht om CM- of AD-algoritmen in de cloud te verfijnen, op basis van de ontvangen en in de cloud gecentraliseerde gegevens.
Voorbeeld van een compressor
Ons softwarekader is toegepast op een compressor die 24/7 draait op onze site in Lommel.
Deze use case bestaat uit een demonstratietoestel en een leerplatform. We hebben snapshots geconfigureerd, onze intelligente triggers gedefinieerd en het kader toegepast op een edge-platform. De intelligente trigger bepaalt de voorwaarden waaronder de edge-apparatuur een volledige snapshot, inclusief ruwe gegevens, naar de cloud moet verzenden.
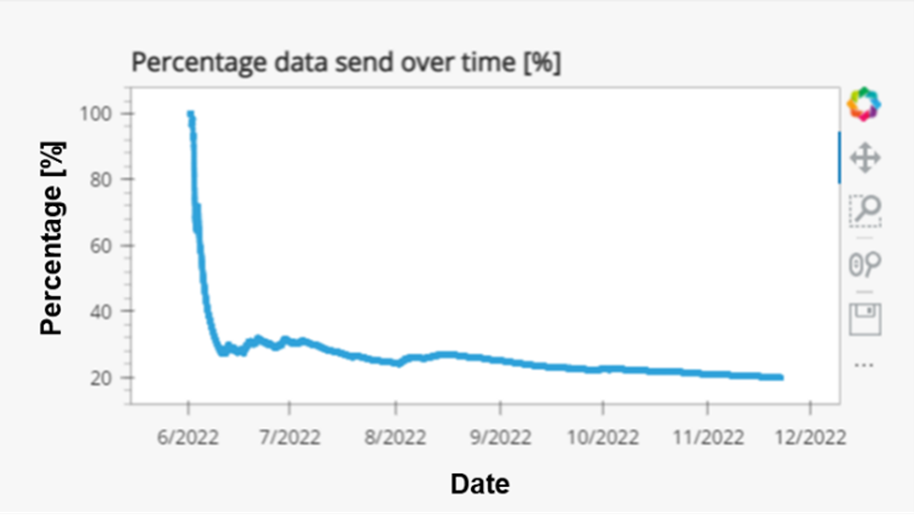
Het resultaat wordt gevisualiseerd op een webpagina (het laden van de pagina kan wat langer duren). Een van de grafieken die we tonen, laat zien dat de hoeveelheid verzonden gegevens in de loop van de tijd vermindert. De onderstaande figuur toont deze informatie voor de voorbije zes maanden. Via onze tool bereikten we een gegevensreductie van +/-80%, waardoor de kosten voor opslag en dataverkeer ook aanzienlijk verminderen.
Conclusie
Binnen dit project hebben we een modulair en gemakkelijk configureerbaar softwarekader ontwikkeld dat op elk edge-platform van een machine kan worden toegepast. Het doel van dit kader is het verkrijgen van een volledige, maar compacte set snapshots van ruwe gegevens van een machine. Onze oplossing uploadt alleen betekenisvolle snapshots van ruwe gegevens naar de cloud, waardoor de overdracht en opslag van redundante gegevens wordt vermeden. De intelligente oplossing voor het vastleggen van gegevens verbetert mettertijd, op basis van reeds verkregen gegevens (en kennis). Door het kader te valideren op een compressor die de afgelopen 6 maanden 24/7 in onze vestiging in Lommel heeft gedraaid, hebben we een gegevensreductie van +-80% bereikt en op die manier de kosten voor opslag en dataverkeer aanzienlijk verminderd.
Referenties
Qiu2020 - Qiu, T., Chi, J., Zhou, X., Ning, Z., Atiquzzaman, M.,Wu, D.O., 2020. Edge computing in industrial internet of things: Architecture, advances and challenges. IEEE Communications Surveys & Tutorials 22, 2462–2488.
Rüßmann2015 - Rüßmann, M., Lorenz, M., Gerbert, P., Waldner, M., Justus, J., Engel, P., Harnisch, M., 2015. Industry 4.0: The future of productivity and growth in manufacturing industries. Boston consulting group 9, 54–89.