Smart machine monitoring based on raw data sets

Smart machine monitoring based on raw data sets
Machine monitoring is the combination of hardware and software tools that allow to evaluate the raw information that is available from the machine. It gives end users a better insight in the reliability and uptime of their industrial machines and captures application knowledge that allows to improve systems/processes as this knowledge provides a better understanding of why these systems/processes might fail.
How does machine monitoring work?
Historically, industrial machines were not connected to the cloud at all. As a consequence, only the local machine controller (edge) could use the collected readings of the machine’s sensors, thus allowing to run various algorithms on these controllers. However, this proved to be very difficult as the lack of easy access to data imposes restrictions on the analysis and further improvement of these algorithms.
In recent years however, the Internet of Things (IoT) and the further development of edge computation has led to:
- Increased connectivity from machine to cloud; and
- Increased computational power on the machine itself{Qiu2020}.
As more and more machines and controllers are being connected to the cloud{Rüßmann2015}, a huge amount of data is becoming available. For instance in a big production line, where a lot of data are generated by a fleet of machines that are operating under similar conditions. As a result, it is now possible to analyse and gather knowledge from existing Condition Monitoring (CM) and/or Anomaly Detection algorithms. These algorithms process the data locally and upload them to the cloud where they are stored and reviewed, either based on user domain knowledge or using machine learning or similar techniques. Still, these collected data are often redundant or not really insightful.
Continuous or periodical monitoring?
There are basically two widely used monitoring systems:
- A system that periodically sends all features to an online database;
- A system that continuously sends all features to an online database.
Both options however, have drawbacks:
- Sending data periodically may result in a dataset that does not show correct transient behaviour and misses critical information to analyse the system, such as potential defects that are only visible in high-frequency raw data signals.
- Sending data continuously will not only result in high data transmission and cloud storage costs, it is also often limited by the bandwidth capacity of your internet connection.
The same logic applies when high-frequency raw data containing valuable machine information are sent to the cloud periodically or continuously. It is a complex story as system manufacturers are cautious about cloud connections and the corresponding safety risks.
Flanders Make framework
Flanders Make developed a software framework with a hybrid approach. On the one hand, we transmit high-frequency raw data, while on the other hand, we aim to reduce the redundancy of the transmitted data as much as possible, resulting in a complete, yet compact and valuable dataset being available in the cloud. We use this framework for (fine)tuning or updating CM and AD parameters, while ensuring feasible transmission and storage requirements. Our framework aims to achieve the following objectives:
- Compact but representative datasets that are sufficiently detailed for further analysis;
- Debugging of the existing application logic;
- Monitoring and training of models.
The framework that we developed is very modular and easily configurable, enabling the adaptation of the specifically targeted dataset according to the acquired knowledge. Such minimal datasets will reduce cloud storage and transmission costs, which are often the biggest cost, and thus allow to eliminate the existing constraints.
The framework is based on local devices (referred to as ‘edge devices’) that – through the data interface – acquire large amounts of data (production data, system identification data...) for later usage in, for instance, control and/or system optimisation. Edge intelligence ensures that only interesting data are sent to the global data storage location (referred to as the ‘cloud’). There can be multiple edge devices (the number of these devices is not predefined or fixed), but there is only one cloud.
The general architecture is presented here:

The main functionalities of the edge are:
- Data retriever: handles different types of data flows (continuous stream of data, event-based data, bursts of high-speed data, metadata)
- Data converter: converts these data into a common data format to be used in the subsequent data flow (called a “snapshot”)
- Feature calculator: provides general “feature calculations” to be used by the intelligent trigger
- Edge storage: storage of local information that the machine already knows so as to avoid redundant data
- Intelligent trigger: a customisable framework allowing to define rules about when to transmit which data
- Data transmitter: ensures that the data are sent from the edge to the cloud
The cloud has the following functionalities:
- Cloud storage: Accepting the data sent by the edge devices and storing it into its database(s) (DB). These data contain both snapshot data (Snapshot DB, containing raw data measurements and features) and processed data that are used as input for the intelligent trigger computations by edge devices (such as a database containing visited operating points – operating point DB)
Other functions that are supported in the cloud:
- Data analysis to improve the “intelligent trigger” in the edge devices. This requires communication from the cloud to the edge devices to update the local triggering activities and the functionality for accessing the data for analysis
- Computational power to refine CM or AD algorithms in the cloud, based on the data received and centralised in the cloud
Compressor example
Our software framework has been implemented on a compressor that runs 24/7 on our site in Lommel.
This use case consists of a demonstrator and a learning platform. We configured snapshots, defined our intelligent triggers and deployed the framework on an edge platform. The intelligent trigger defines the conditions in which the edge needs to transmit a full snapshot, including the raw data, to the cloud.
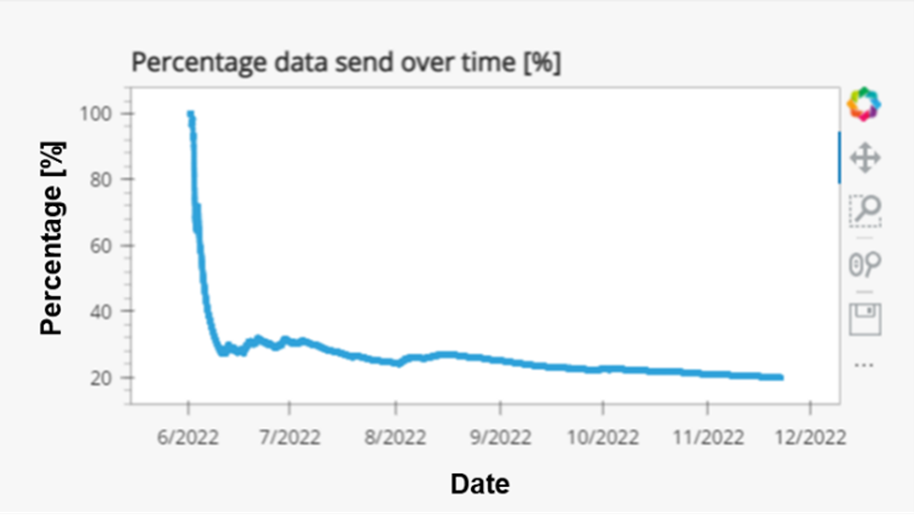
The result is visualised on a webpage (loading the page can take a minute). One of the graphs that we show, shows the amount of data sent decreases over time. The figure below shows this information for the past six months. Through our tool, we achieved a data reduction of +/-80%, also significantly reducing storage and data traffic costs.
Conclusion
Within this project, we have developed a modular and easily configurable software framework that can be deployed on any edge platform of a machine. The goal of this framework is to obtain a complete, yet compact set of raw data snapshots of a machine. Our solution only uploads snapshots of raw data that are of interest to the cloud, avoiding the transmission and storage of redundant data. The intelligent data capturing solution improves over time, based on already obtained data (and knowledge). By validating the framework on a compressor that runs 24/7 over the past 6 months in our Lommel facility, we achieved a data reduction of +-80%, resulting in less storage and data traffic costs.
References
Qiu2020 - Qiu, T., Chi, J., Zhou, X., Ning, Z., Atiquzzaman, M.,Wu, D.O., 2020. Edge computing in industrial internet of things: Architecture, advances and challenges. IEEE Communications Surveys & Tutorials 22, 2462–2488.
Rüßmann2015 - Rüßmann, M., Lorenz, M., Gerbert, P., Waldner, M., Justus, J., Engel, P., Harnisch, M., 2015. Industry 4.0: The future of productivity and growth in manufacturing industries. Boston consulting group 9, 54–89.